

クリエイターなら誰もが一度は夢見る光景です。
動画生成AIの登場は、その夢を現実のものにしてくれると期待されました。しかし、多くのクリエイターが直面したのは、「うちの子が、AIによって別人になってしまう」という悪夢でした。ガーン。
生成するたびに顔が変わる。手足は崩れる。何度やり直しても、思い描いたキャラクターはそこにいません。この*キャラクター崩壊」という大きな壁のせいで、「AIでのアニメ制作はまだ無理だ」と諦めかけていた方も多いのではないでしょうか。

しかし、その常識はもう過去のものになるかもしれません。
動画生成AI「Vidu Q1」に搭載されたある画期的な機能が、この長年の課題に終止符を打ちます。それは、クリエイターがAIを完全にコントロールし、「うちの子」の一貫性を保ったまま、命を吹き込むことを可能にするブレークスルー!
この記事では、私が実際にその機能を使って制作したオリジナルアニメ「ふたりの赤ちゃん」をお見せしながら、誰でも簡単に高品質なオリキャラアニメを制作できる具体的な方法を、プロンプトの例を交えて徹底的に解説します。
Vidu Q1がもたらしたブレークスルー:高画質リファレンス機能という光
「うちの子が、AIによって別人になってしまう」という悪夢を劇的に変えたのが、Vidu Q1に搭載された高画質なリファレンス機能です。
この機能の仕組みは非常にシンプルです。
「このキャラクターを、この絵柄で動かしてください」という『お手本』となる画像をAIに提示する。たったこれだけです。
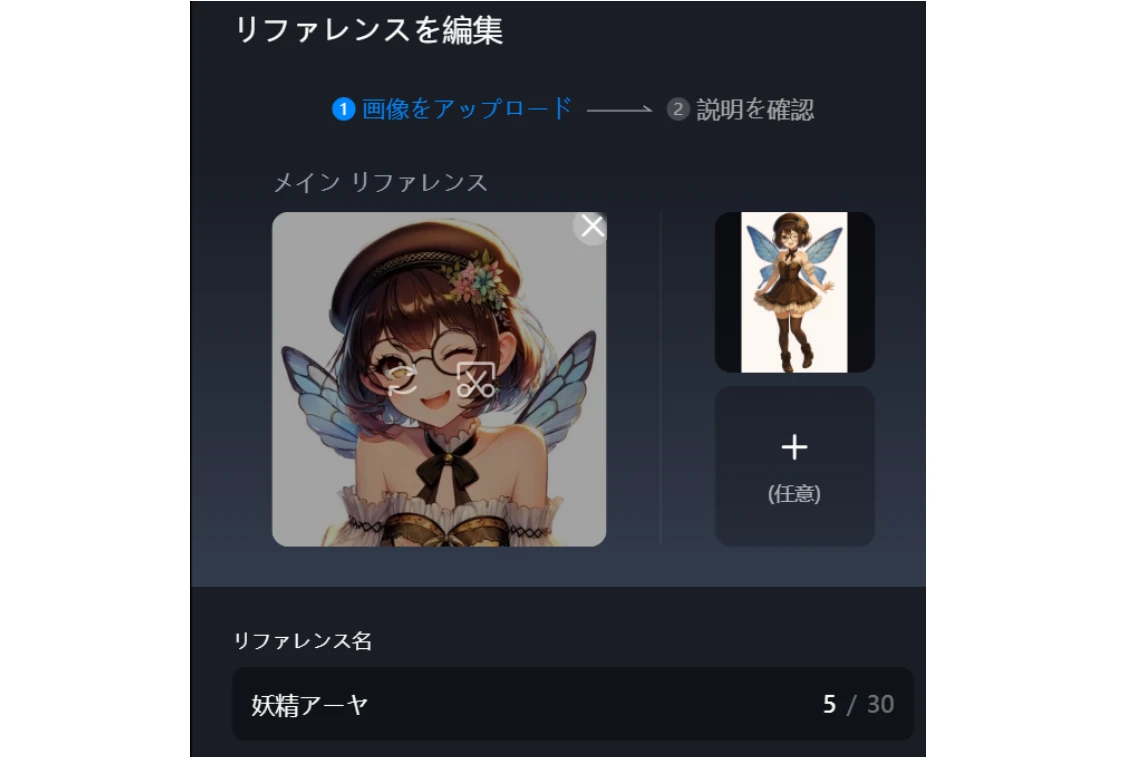
ViduのAIは、提示されたリファレンス画像からキャラクターの持つ特徴——髪の色や髪型、目の形、服装、そして全体的な絵のタッチ——を驚くほど高い精度で抽出します。そして、その特徴を維持したまま、プロンプトで与えられた指示(動きや表情、シチュエーション)に従ってアニメーションを生成するのです。
これにより、先ほど挙げた課題の多くが解決へと向かいました。
- 圧倒的なキャラクター一貫性:リファレンス画像という絶対的な基準があるため、何度生成しても同じキャラクターが登場します。「キャラ崩壊」の恐怖から解放され、クリエイターは安心して物語の創造に集中できるようになりました。
- 破綻の大幅な減少:リファレンス画像の絵柄や画風を維持しようとするためか、不自然なディテールの破綻が大幅に減少しました。もちろんゼロではありませんが、一昔前とは比較にならないほど安定しています。
- 表現力豊かな表情と滑らかな動き:AIはリファレンス画像のキャラクターが「どう笑うか」「どう怒るか」を、その絵柄の中で解釈して表現します。その結果、キャラクターの個性を損なうことなく、非常に自然で感情豊かな表情や動きが生まれるようになりました。
これは単なる機能改善ではありません。クリエイターがAIを「制御不能な気まぐれなアシスタント」ではなく、「言うことを聞いてくれる優秀なアニメーター」として扱えるようになった、革命的な変化なのです。
【実践】Vidu Q1でオリキャラを動かしてみた!「ふたりの赤ちゃん」制作秘話

理論はさておき、実際にどれほどのことができるのか、見ていただくのが一番早いでしょう。今回、私はVidu Q1のリファレンス機能のポテンシャルを測るため、オリジナルの2Dアニメーション「ふたりの赤ちゃん」を制作してみました。
https://youtu.be/Hs_w35E3BJsこのセクションでは、この短いアニメーションをどのようにして制作したのか、そのプロセスと工夫した点をご紹介します。
なぜ「ふたりの赤ちゃん」をテーマにしたのか?

今回、私がテーマに「ふたりの赤ちゃん」を選んだのには、いくつかの明確な理由があります。これはVidu Q1の性能をテストするための、私なりの実験計画でもありました。
- テスト1:表情の多様性
赤ちゃんは、感情表現が非常に豊かでストレートです。満面の笑み、大声での号泣、驚き、怒りなど、喜怒哀楽がはっきりと顔に出ます。Vidu Q1が、リファレンス画像のキャラクターの個性を保ったまま、どこまで繊細な表情の変化を描き分けられるかテストするのに最適な題材でした。 - テスト2:複数キャラクターのインタラクション
AIにとって、複数のキャラクターを同時に、かつ自然に動かすことは非常に難しいタスクです。キャラクター同士が干渉しあって混ざってしまったり、片方のキャラクターが消えてしまったりすることがよくあります。「ふたりの赤ちゃん」が一緒に遊んだり、喧嘩したりするシーンを生成することで、Vidu Q1が複数キャラクターの相互作用をどれだけ正確にハンドリングできるかを確認したかったのです。 - テスト3:絵柄の一貫性
シンプルながらも特徴のあるキャラクターデザインを用意し、様々なシーンを生成しても絵柄やキャラクターデザインが崩れないかを試しました。アニメのような、ある程度デフォルメされた絵柄でもAIが正しく認識・再現できるかを見るのが目的でした。
これらのテストを通じて、Vidu Q1のリファレンス機能の実用的な限界と可能性を探ろうと考えたのです。
成功の鍵を握る「リファレンス画像」準備のコツ
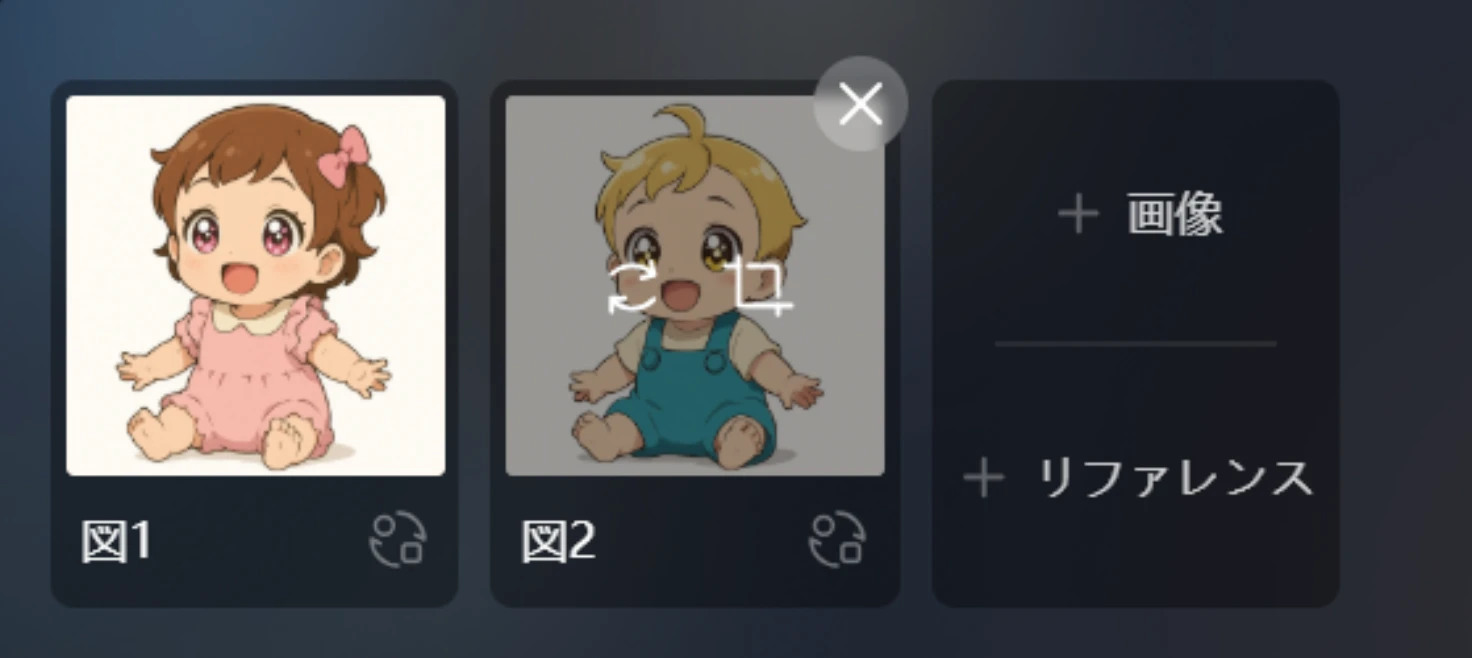
Vidu Q1のリファレンス機能は非常に優秀ですが、その性能を最大限に引き出すには、インプットとなる「リファレンス画像」の質が極めて重要です。今回、私が「ふたりの赤ちゃん」のために用意したリファレンス画像は、以下のようなものです。
私がリファレンス画像を用意する際に心がけているポイントは下記です。
- キャラクターの特徴を明確にする
AIがキャラクターを認識しやすいよう、背景はシンプル(白や単色など)にし、キャラクターがはっきりと見えるようにします。解像度が高い方がもちろんいいです。 - 2Dアニメの場合は、色がセル画だとわかりやすいべた塗りのものを用意
2Dアニメの場合は、色の塗り方がべた塗りのものを用意するとリファレンス時に崩れにくくなります。(逆に塗り方の濃淡が繊細なものだと崩れやすい傾向があります) - (可能であれば)角度のバリエーションを用意する
これは必須ではありませんが、より高度なコントロールを目指すなら横の姿や後ろ姿も登録するとよいです。今回は男女それぞれで1枚ずつ、基本的な正面の画像を使用しました。個人的にはシンプルなちびキャラであれば1枚で十分です。(横や後ろに特徴的なものがある場合を除く)
このように、少し手間をかけてリファレンス画像を用意するだけで、生成されるアニメーションのクオリティは劇的に向上します。自分の「オリキャラ」を動かしたい方は、ぜひこだわってみてください。
【チュートリアル】Vidu Q1プロンプト&リファレンス活用術
それでは、いよいよ具体的な制作手順の解説です。
「ふたりの赤ちゃん」の制作で実際に使用したリファレンス画像とプロンプトの組み合わせをご紹介します。プロンプトのどの部分が、どのような効果をもたらすのか、ぜひ参考にしてみてください。
海で泣く赤ちゃん
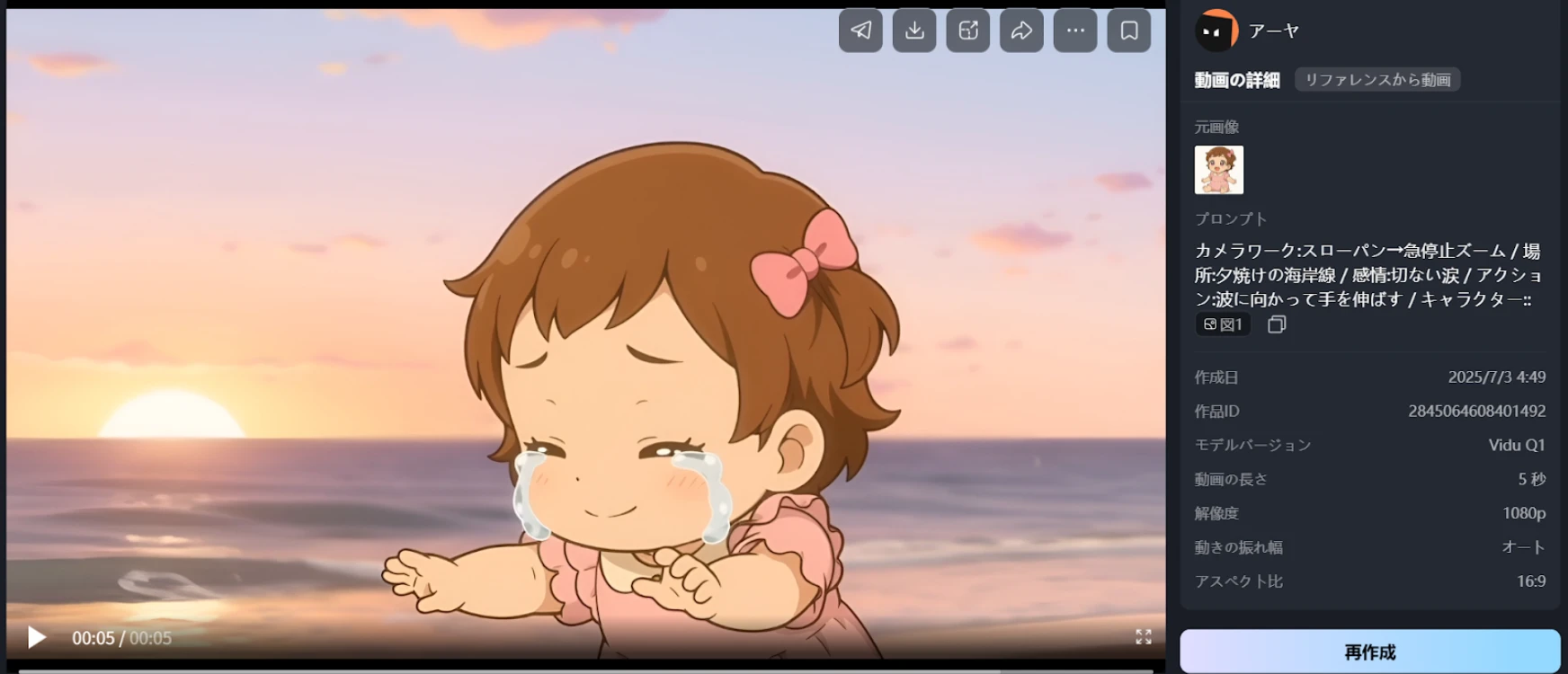
プロンプト:
カメラワーク:スローパン→急停止ズーム/場所:夕焼けの海岸線/感情:切ない涙/アクション:波に向かって手を伸ばす/キャラクター:[@図1]
サーキットで競争する赤ちゃん
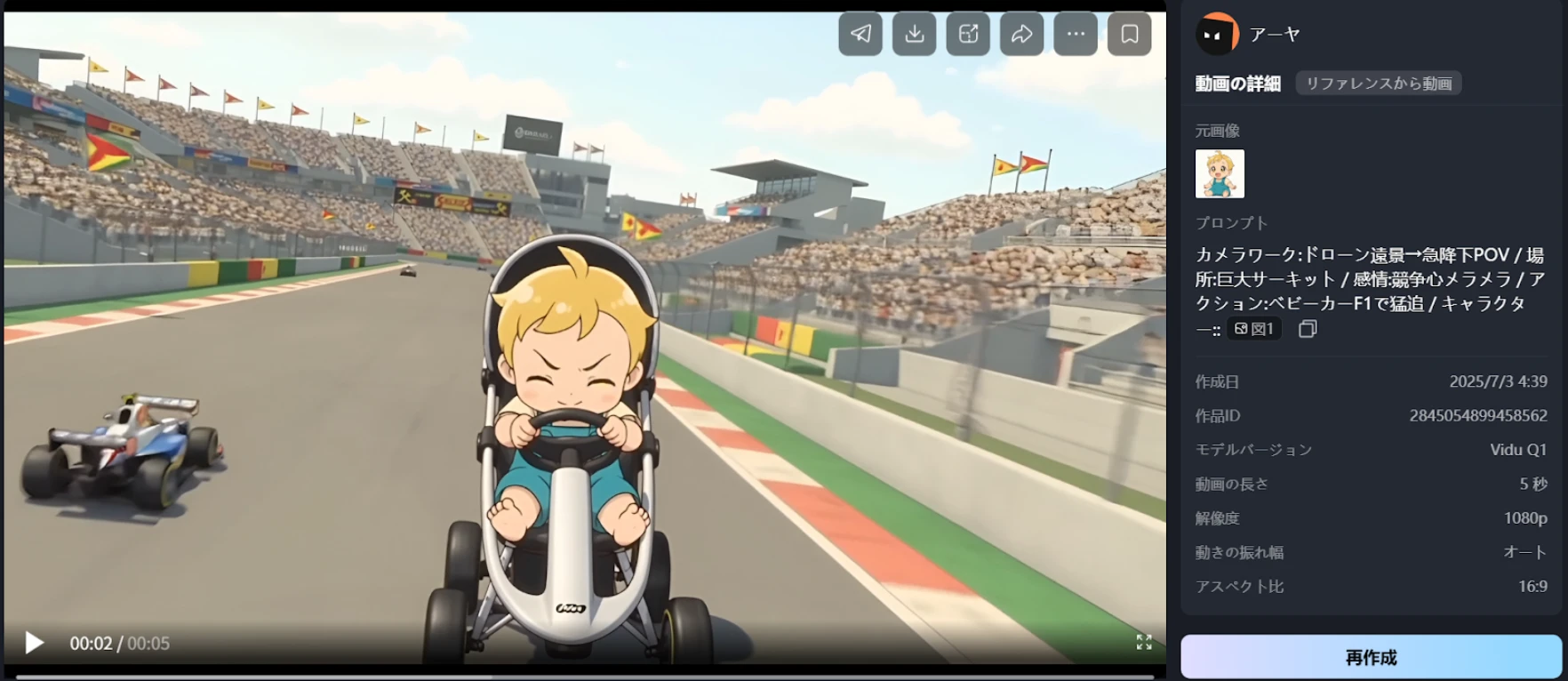
プロンプト:
カメラワーク:ドローン遠景→急降下POV/場所:巨大サーキット/感情:競争心メラメラ/アクション:ベビーカーF1で猛追/キャラクター::[@図1]
図書館の天井迷路でわくわくする赤ちゃん

プロンプト:
カメラワーク:トップダウン→縦回転反転/場所:図書館の天井迷路/感情:好奇心MAX/アクション:浮遊本を追って空中遊泳/キャラクター::[@図1]
レースコースでわくわくする赤ちゃん
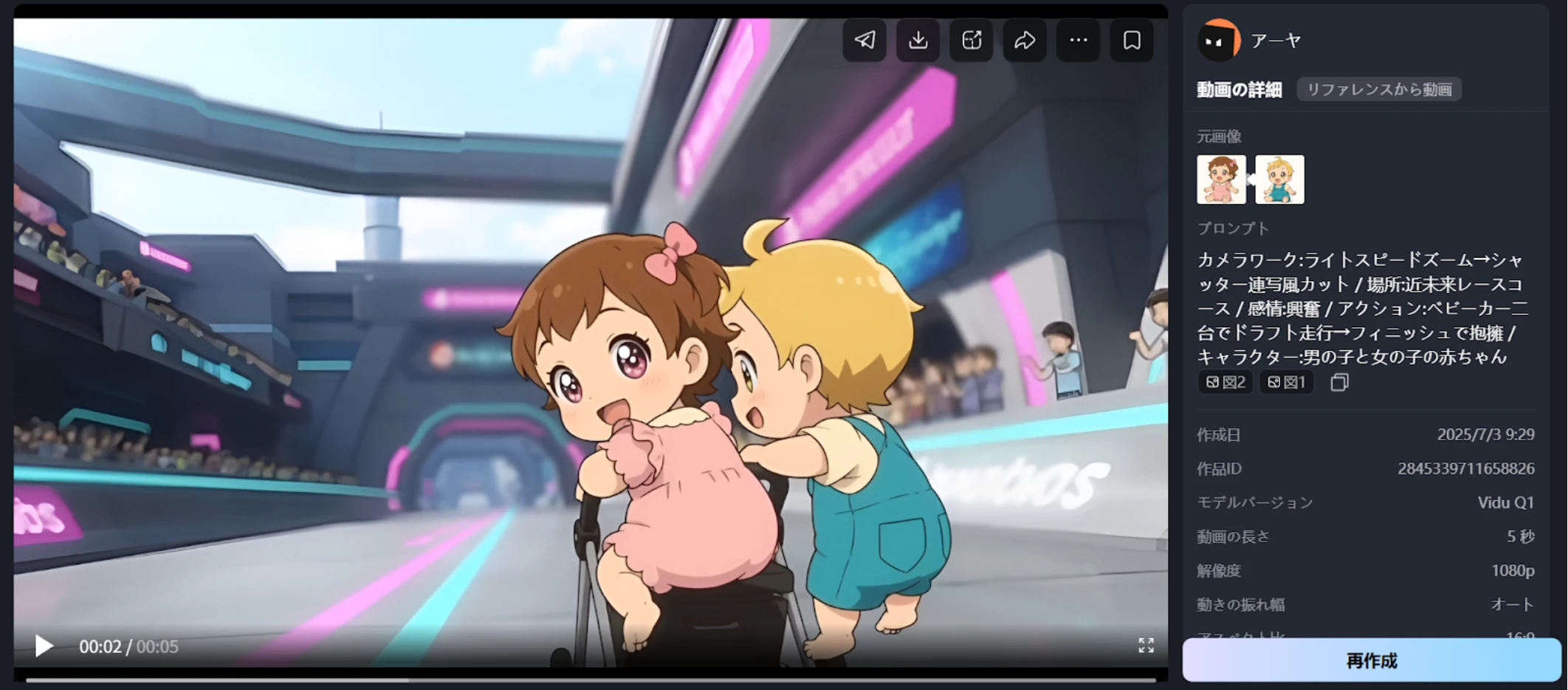
プロンプト:
カメラワーク:ライトスピードズーム→シャッター連写風カット/場所:近未来レースコース/感情:興奮/アクション:ベビーカー二台でドラフト走行→フィニッシュで抱擁/キャラクター:男の子と女の子の赤ちゃん[@図2][@図1]
Vidu Q1の現在地と未来への期待
さて、ここまでVidu Q1のリファレンス機能を使った具体的な制作プロセスを見てきました。最後に、その実力を客観的に評価し、今後の可能性について考察してみたいと思います。
商用利用は可能か?破綻の現状と対策
「このクオリティなら、もう仕事で使えるのでは?」
そう思われた方もいらっしゃるかもしれません。私の個人的な見解としては、「限定的な条件下であれば、商用利用も視野に入るレベルにほぼ近づいている」と感じています。
「ふたりの赤ちゃん」の制作過程でも明らかになったように、キャラクターの一貫性や表情の豊かさ、動きの滑らかさは、従来のAI動画生成ツールとは一線を画します。特に、SNS用のショートアニメや、Web広告、VTuberのOP/ED映像など、短い尺の映像制作においては、強力な武器になるでしょう。
しかし、「破綻がまったく起きないわけではない」という事実も、正直にお伝えしなければなりません。
特に、以下のようなケースでは破綻が起きやすくなります。
- 複雑なアクション:走る、踊る、戦うといった、全身を使った激しい動き。
- 精密な手の動き:何かを掴む、指をさすなど、指先の細かい表現。
- ダイナミックなカメラワーク:キャラクターを追いかけながら回り込むような複雑なカメラの動き。
これらの苦手な部分をAIだけに任せようとすると、やはり不自然な結果が生まれがちです。
対策として有効なのは「AIとの分業」です。例えば、得意な「キャラクターの表情やバストアップの動き」はViduで生成し、苦手な「複雑なアクション」の部分は手描きで作画したり、他のツールを組み合わせたりする。このように、AIを万能の魔法としてではなく、制作フローの一部を効率化する「優秀なツール」として捉えることで、商用レベルのクオリティと制作スピードを両立できる可能性が見えてきます。
さらなる進化への期待:Viduに望む未来の機能
Vidu Q1は素晴らしいツールですが、クリエイターとしては、さらなる高みを望んでしまいます。今後のアップデートで実装されたら、創作の自由度が爆発的に向上するだろうと期待している機能が2つあります。
- 構図・デッサン参照機能(ControlNetのような機能)
現在はリファレンス画像で「キャラクター」を指定できますが、これに加えて「構図」も指定できると、さらに表現の幅が広がります。例えば、簡単な棒人間のデッサン画像を読み込ませて、「このポーズで、このキャラクターを動かして」と指示できる機能です。これが実現すれば、より意図した通りのアクションやカメラアングルを正確に作り出すことができ、アニメーション制作の自由度は飛躍的に向上するでしょう。 - リファレンス画像からの画像生成機能(Image to Image)
現状のViduは、テキストやリファレンス画像から「動画」を生成しますが、リファレンス画像を元に、少しだけ変化を加えた「静止画」を生成する機能(いわゆるImage to Image)が搭載されると、さらに便利になります。例えば、リファレンス画像のキャラクターに「笑った顔」の静止画をまず作らせ、それを新たなリファレンスとして動画を生成する…といった、より段階的で緻密なワークフローが可能になります。
これらの機能が追加されれば、Viduは単なる動画生成ツールから、総合的なビジュアルコンテンツ制作プラットフォームへと進化を遂げるはずです。今後のアップデートに、心から期待しています。
まとめ
今回は、動画生成AI「Vidu Q1」の高画質リファレンス機能が、いかにオリキャラの2Dアニメ制作を革新したかをご紹介しました。
- Vidu Q1のリファレンス機能は、「キャラ崩壊」という長年の課題を解決し、キャラクターの一貫性を劇的に向上させた。
- 実際に制作した「ふたりの赤ちゃん」では、豊かな表情や複数人のインタラクションなど、高い表現力を確認できた。
- プロンプトを工夫することで、喜び、怒り、共演といった様々なシーンを意図通りに生成可能。
- 破綻はゼロではないものの、AIをツールとして賢く利用すれば、商用レベルの制作も視野に入る。
- 今後は「構図参照」や「Image to Image」機能の搭載に期待したい。

AIによるアニメーション制作は、もはや「夢物語」や「お遊び」ではありません。クリエイターの創造性を拡張し、個人でもハイクオリティな映像作品を生み出せる時代が、もうそこまで来ています。
この記事を読んで、「自分もオリキャラを動かしてみたい!」と少しでも感じていただけたなら、これほど嬉しいことはありません。ぜひ、あなただけのキャラクターで、Viduを使ったAIアニメ制作に挑戦してみてください。きっと、想像を超える感動が待っていますよ。

